Информатика Профиль 10кл.
Курс «Информатика», 10 класс, Профиль
1 сентября 2020, 00:00 - 31 мая 2021, 00:00, Проводится
Структура информации, графы.
Сравним четыре сообщения.
Первое:
«Для того чтобы добраться из Москвы до села Васино, нужно сначала долететь на самолёте до города Ивановска. Затем на электричке доехать до Ореховска. Там на пароме переправиться через реку Слоновую в посёлок Ольховка, и оттуда ехать в село Васино на попутной машине».
Второе:
«Как ехать в Васино:
1. На самолёте из Москвы до г. Ивановска.
2. На электричке из г. Ивановска до г. Ореховска.
3. На пароме из г. Ивановска через р. Слоновую в пос. Ольховка.
4. На попутной машине из пос. Ольховка до с. Васино».
Третье:
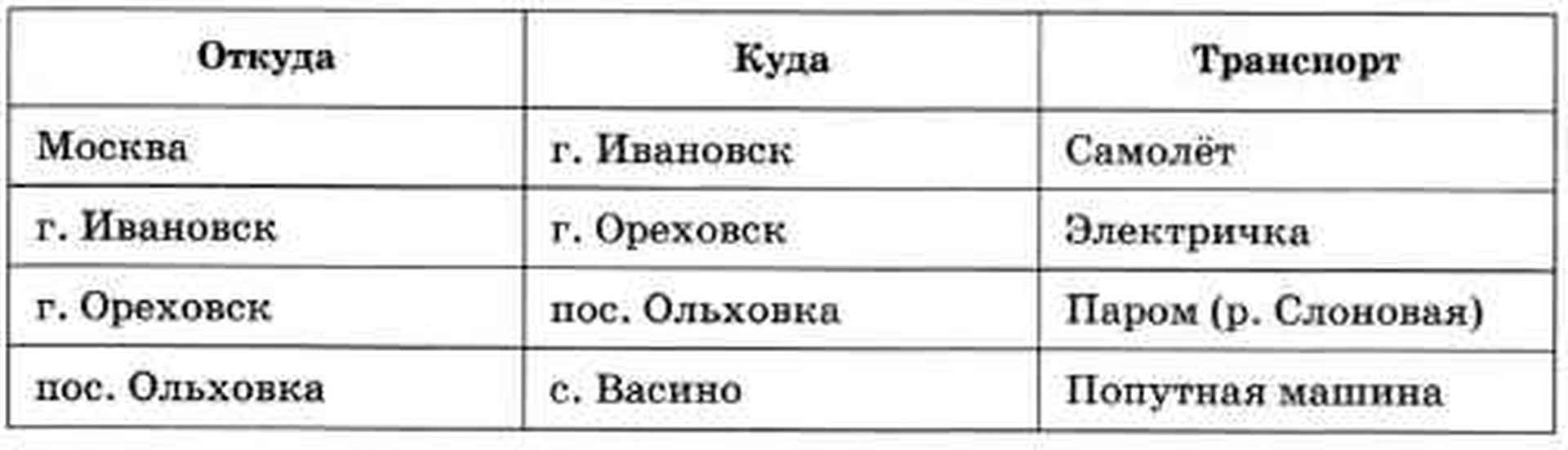
Четвёртое:

Можно считать, что все эти (такие разные по форме!) сообщения содержат одну и ту же информацию. Какие из них проще воспринимать? Очевидно, что человеку «вытащить» полезную информацию из сплошного текста (первое сообщение) сложнее всего. Во втором случае мы сразу видим все этапы поездки и понимаем, в каком порядке они следуют друг за другом. Третье сообщение (таблицу) и четвёртое (схему) можно понять сразу, с первого взгляда. Второй, третий и четвёртый варианты воспринимаются лучше и быстрее первого, потому что в них выделена структура информации, в которой самое главное — этапы поездки в Васино.
Зачем книгу разбивают на главы и разделы, а не пишут сплошной текст? Зачем в тексте выделяют абзацы? Прежде всего для того, чтобы подчеркнуть основные мысли, — каждая глава, раздел, абзац содержат определённую идею. Благодаря особенностям человеческого восприятия, при таком выделении структуры улучшается передача информации от автора к читателю.
При автоматической (компьютерной) обработке правильно выбранная структура данных облегчает доступ к ним, позволяет быстро найти нужные данные.
Средства, облегчающие поиск информации, знакомы вам по работе с книгами. Самый простой (но очень утомительный!) способ найти в книге то, что нужно, — перелистывать страницу за страницей. Однако в большинстве книг есть оглавление, которое позволяет сразу найти нужный раздел, и это значительно ускоряет поиск.
В словарях слова всегда расставлены в алфавитном порядке (представьте себе, что было бы, если бы они были расположены произвольно!). Поэтому, открыв словарь в любом месте, мы можем сразу определить, куда дальше листать страницы для поиска нужного слова — вперёд или назад.
В больших книгах используют указатели (индексы) — списки основных терминов с указанием страниц, на которых они встречаются.

Структурирование — это выделение важных элементов в информационных сообщениях и установление связей между ними.
Цели структурирования для человека — облегчение восприятия и поиска информации, выявление закономерностей. При компьютерной обработке структурирование ускоряет поиск нужных данных.
С некоторыми структурами данных вы уже знакомы. Например, на уроках математики вы изучали множество — некоторый набор элементов. Чтобы определить множество, мы должны перечислить все его элементы (например, множество, состоящее из Васи, Пети и Коли) или определить характерный признак, по которому элементы включаются в это множество (например, множество драконов с пятью зелёными хвостами или множество точек, в которых функция принимает положительные значения).
Множество может состоять из конечного числа элементов (множество букв русского алфавита), бесконечного числа элементов (множество натуральных чисел) или вообще быть пустым (множество слонов, живущих на Северном полюсе). Множества, с которыми работает компьютер, не могут быть бесконечными, потому что его память конечна.
В документах множество часто оформляют в виде маркированного списка, например:
- процессор;
- память;
- устройства ввода;
- устройства вывода.
В таком списке порядок элементов не важен, от перестановки элементов множество не меняется
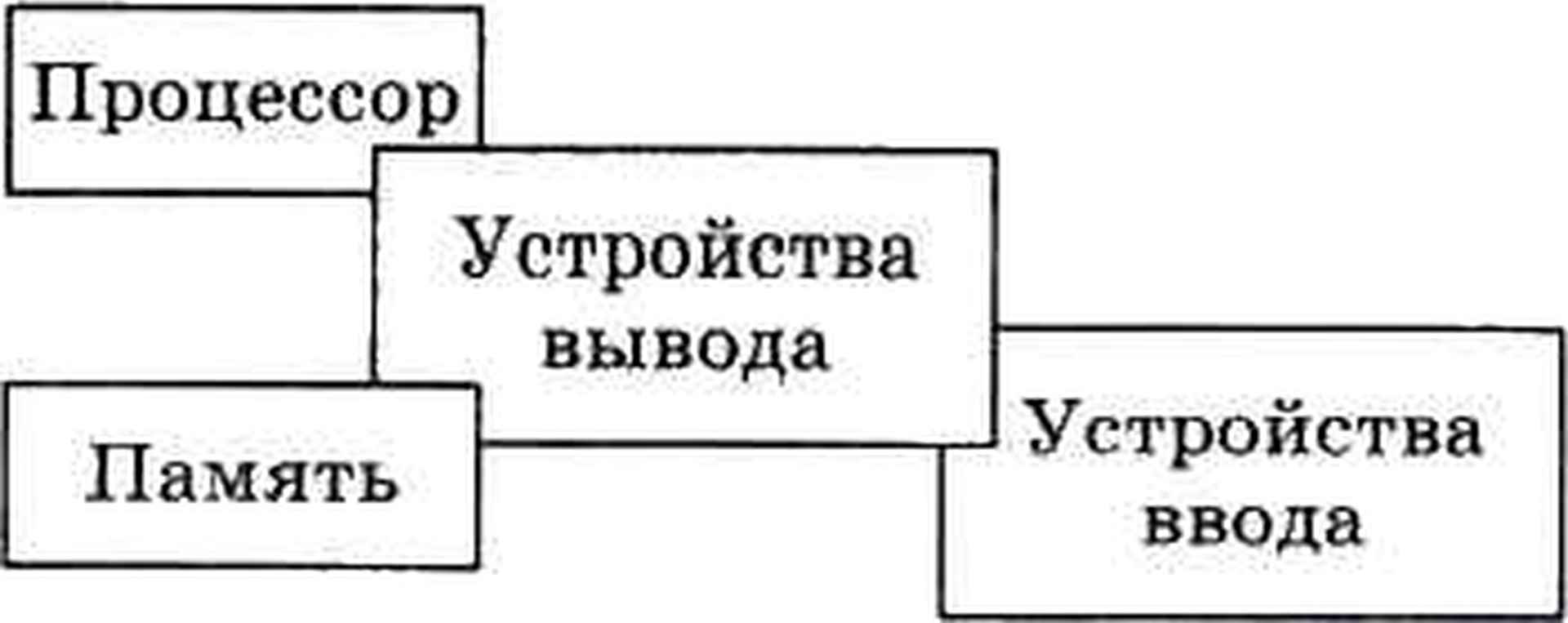
Линейный список состоит из конечного числа элементов, которые должны быть расположены в строго определённом порядке.
В отличие от множества элементы в списке могут повторяться. Список обычно упорядочен (отсортирован) по какому-то правилу, например по алфавиту, по важности, по последовательности действий и т. д. В тексте он часто оформляется как нумерованный список, например:
- надеть носки;
- надеть ботинки;
- выйти из дома.

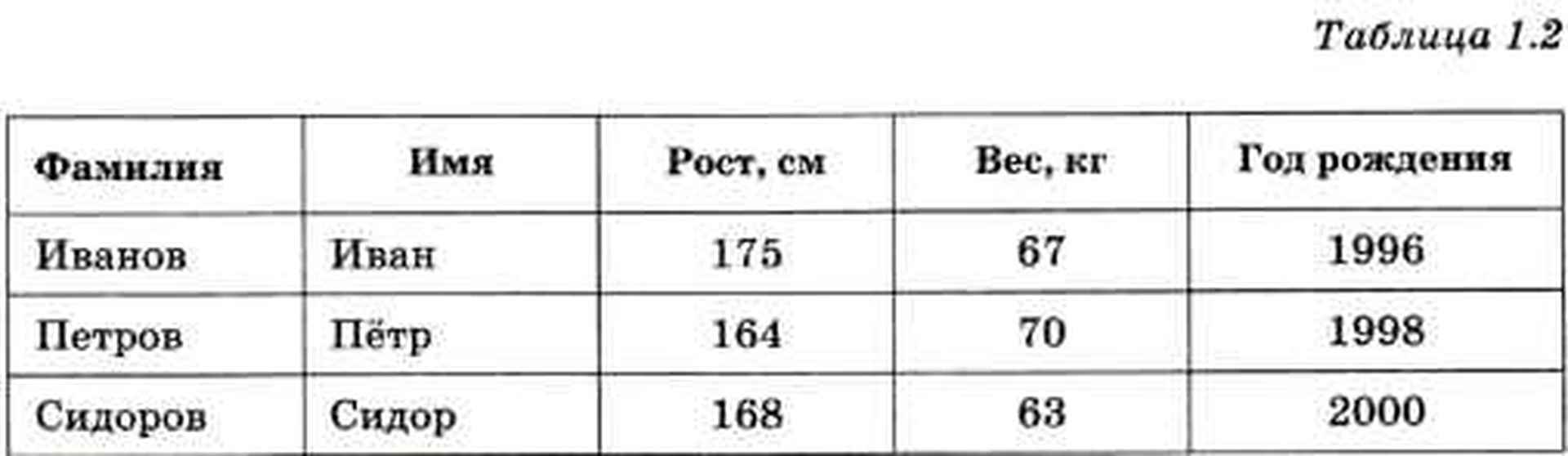
Именно так хранится информация в базах данных: строка таблицы, содержащая информацию об одном объекте, называется записью, а столбец (название свойства) — полем.
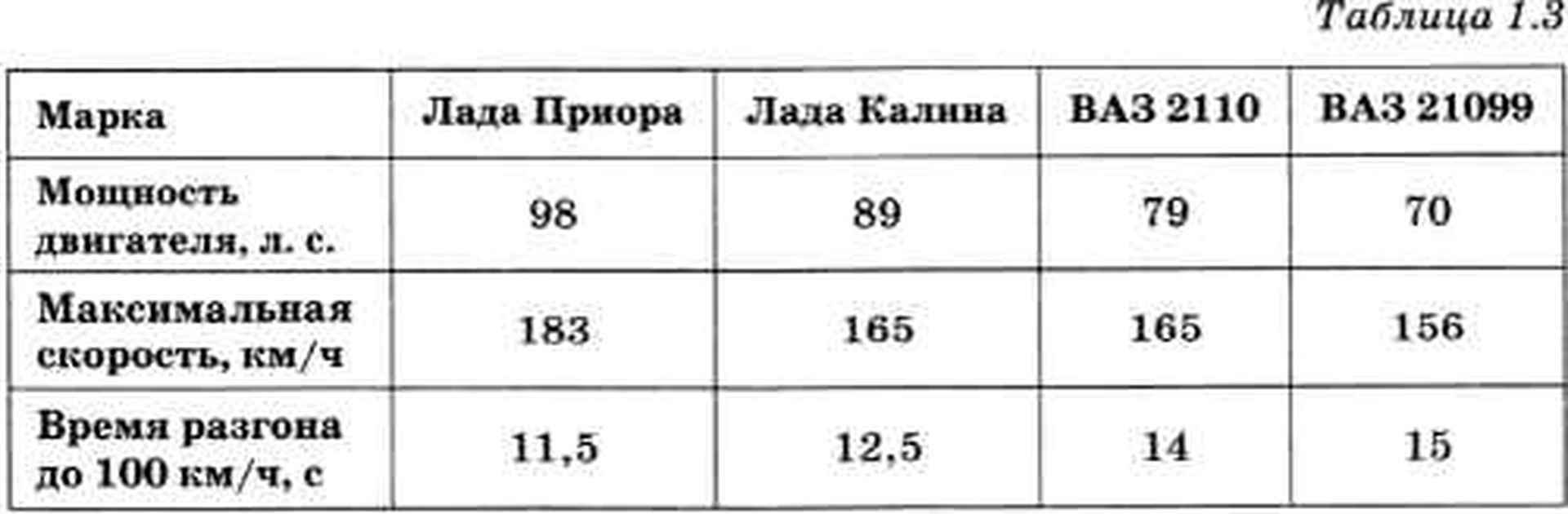
Возможен и другой вариант таблицы, когда роли строк и столбцов меняются. В первом столбце записываются названия свойств, а данные в каждом из следующих столбцов описывают свойства какого-то объекта. Например, следующая таблица содержит характеристики разных марок автомашин.
Линейных списков и таблиц иногда недостаточно для того, чтобы представить все связи между элементами. Например, в некоторой фирме есть директор, ему подчиняются главный инженер и главный бухгалтер, у каждого из них есть свои подчинённые. Если мы захотим нарисовать схему управления этой фирмы, она получится многоуровневой (рис. а).
Такая структура, в которой одни элементы «подчиняются» другим, называется иерархией. В информатике иерархическую структуру называют деревом. Дело в том, что, если перевернуть схему на рисунке вверх ногами, она становится похожа на дерево (точнее, на куст, см. рис б).
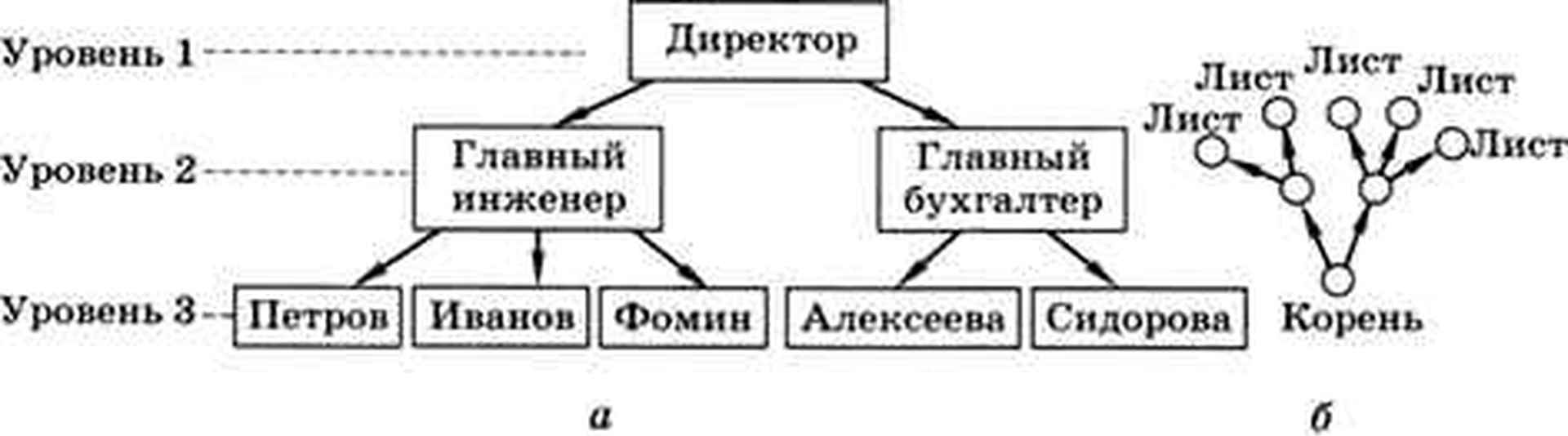
Дерево состоит из узлов и связей между ними (они называются дугами). Самый первый узел, расположенный на верхнем уровне (в него не входит ни одна стрелка-дуга), — это корень дерева. Конечные узлы, из которых не выходит ни одна дуга, называются листьями. Все остальные узлы, кроме корня и листьев, — промежуточные.
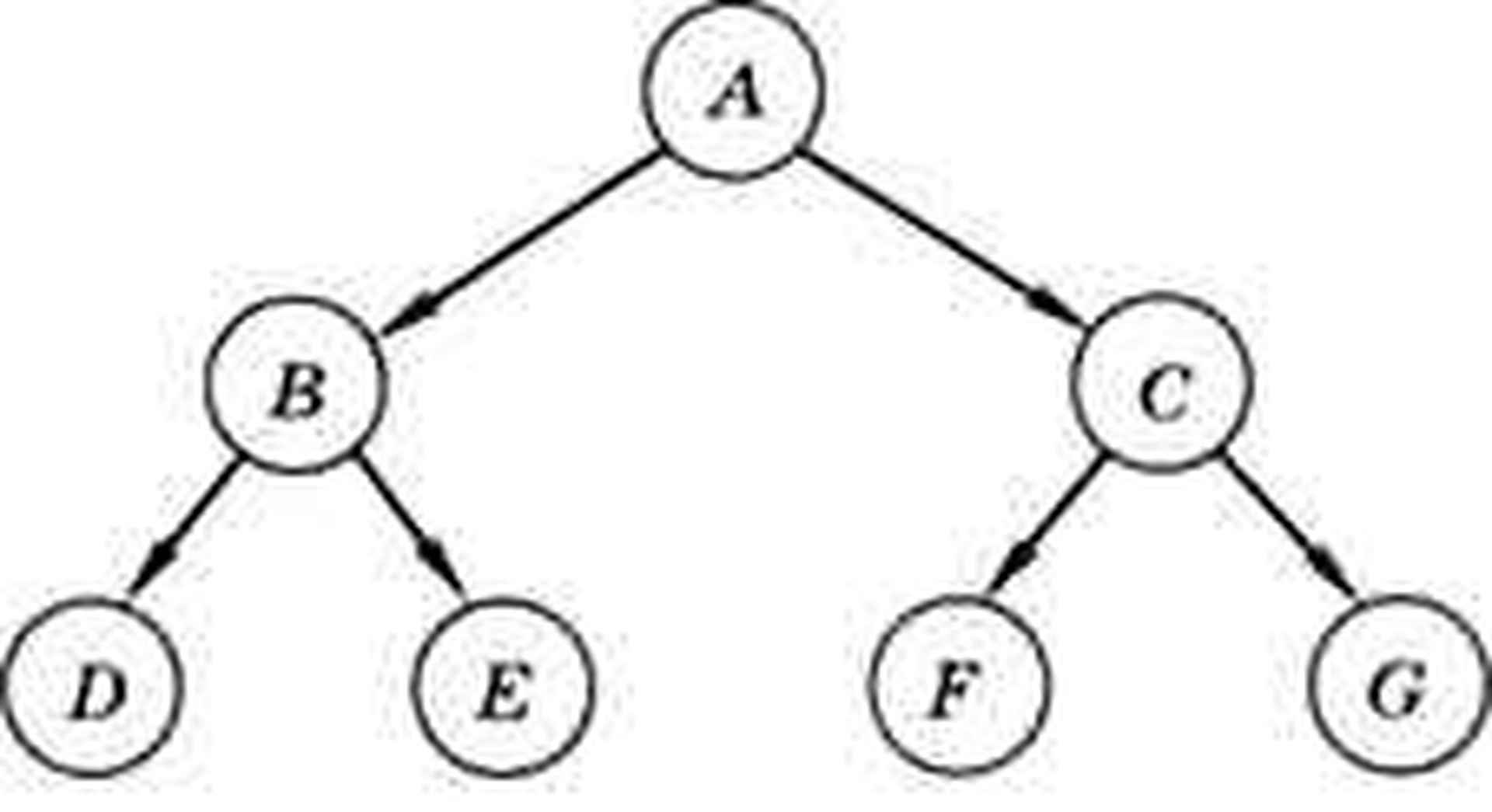
Из двух связанных узлов тот, который находится на более высоком уровне, называется родителем, а другой — сыном. Корень — это единственный узел, у которого нет родителя; у листьев нет сыновей.
Используются также понятия предок и потомок. Потомок какого-то узла — это узел, в который можно перейти по стрелкам от узла-предка. Соответственно, предок какого-то узла — это узел, из которого можно перейти по стрелкам в данный узел.
В дереве на рисунке ниже родитель узла Е — это узел В, а предки узла Е — это узлы А я В, для которых узел Е — потомок. Потомками узла А (корня) являются все остальные узлы.
Типичный пример иерархии — различные классификации (животных, растений, минералов, химических соединений). Например, отряд Хищные делится на два подотряда: Псообразные и Кошкообразные. В каждом из них выделяют несколько семейств.
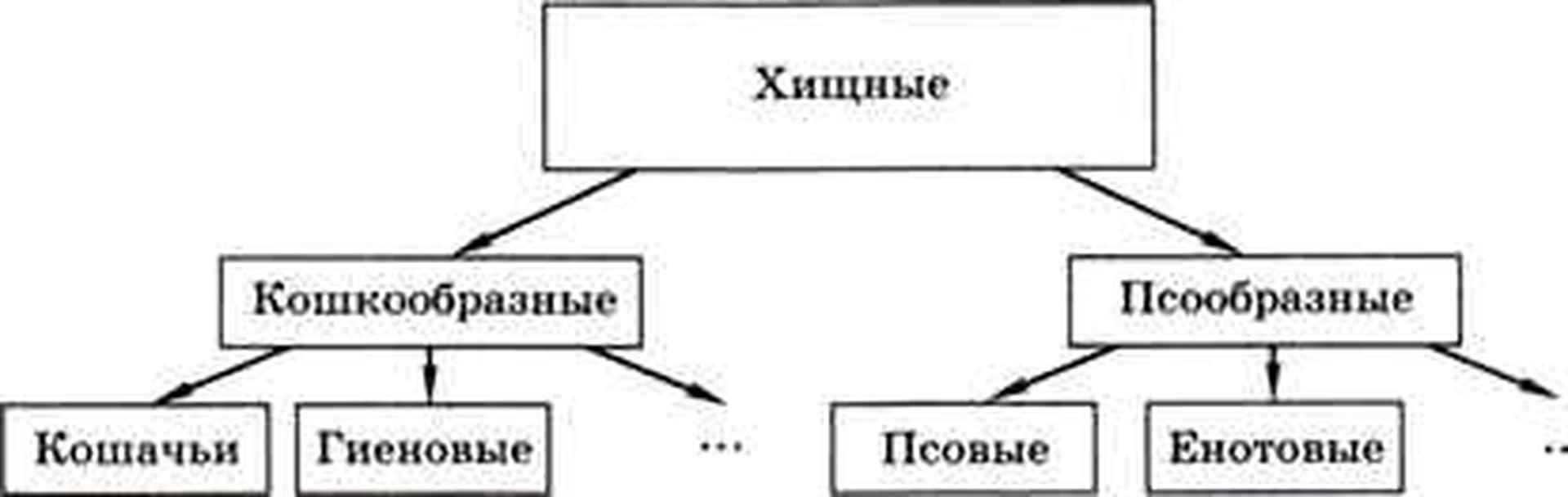
Конечно, на рисунке показаны не все семейства, остальные обозначены многоточиями.
В текстах иерархию часто представляют в виде многоуровневого списка. Например, оглавление книги о хищниках может выглядеть так:
Глава 1. Псообразные
1.1. Псовые
1.2. Енотовые
1.3. Медвежьи
...
Глава 2. Кошкоообразные
2.1. Кошачьи
2.2. Гиеновые
2.3. Мангустовые
...
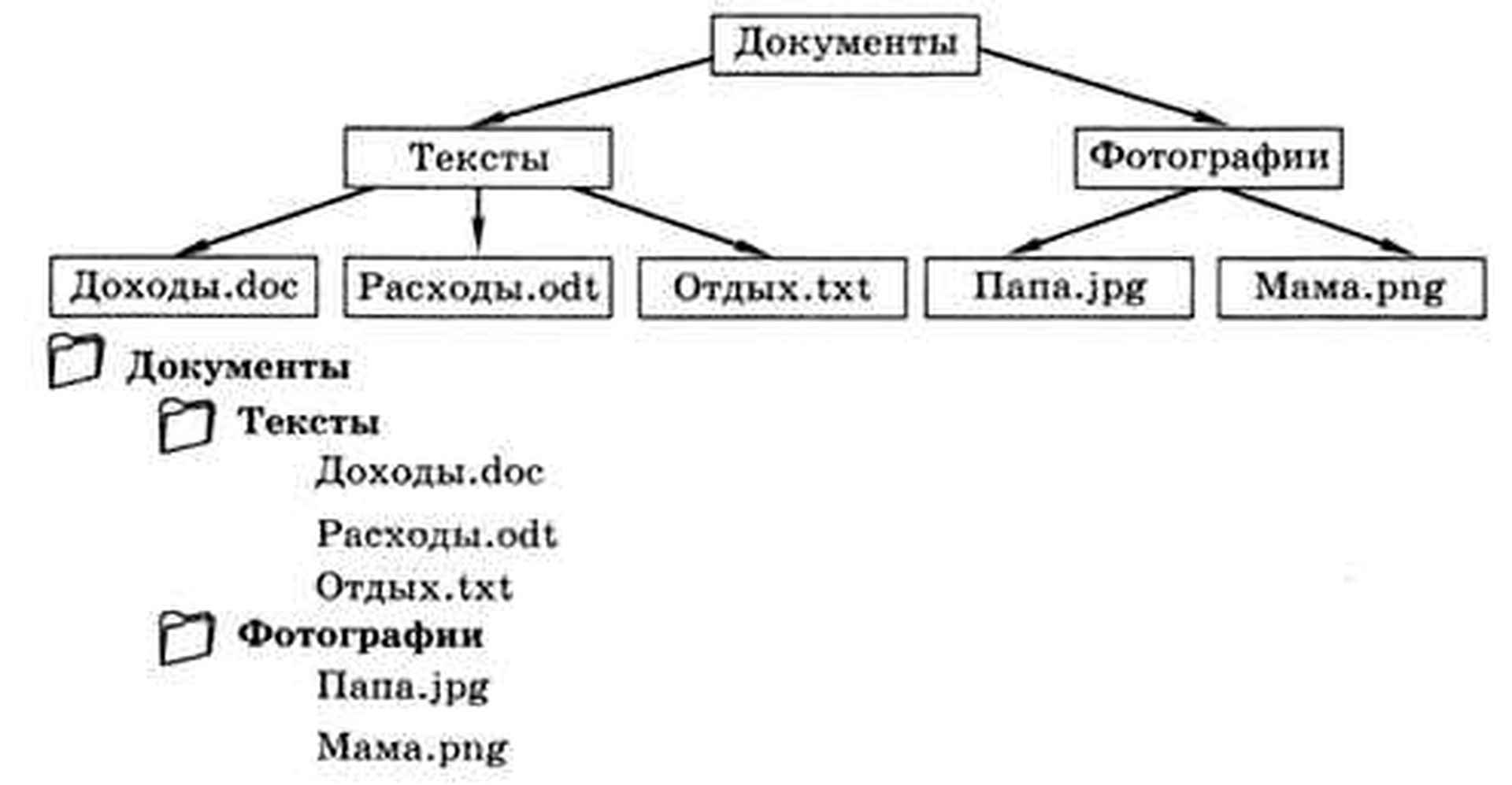
Работая с файлами и папками, мы тоже встречаемся с иерархией: классическая файловая система имеет древовидную структуру. Вход в папку — это переход на следующий (более низкий) уровень иерархии (рис. 1.14).
В современных файловых системах (NTFS, ext3) файл может «принадлежать» нескольким каталогам одновременно. При этом древовидная структура, строго говоря, нарушается.
СТРУКТУРНОЕ ПРЕДСТАВЛЕНИЕ ЧИСЕЛ.
Алгоритм вычисления арифметического выражения тоже может быть представлен в виде дерева.
(а + 3) * 5 - 2 * b
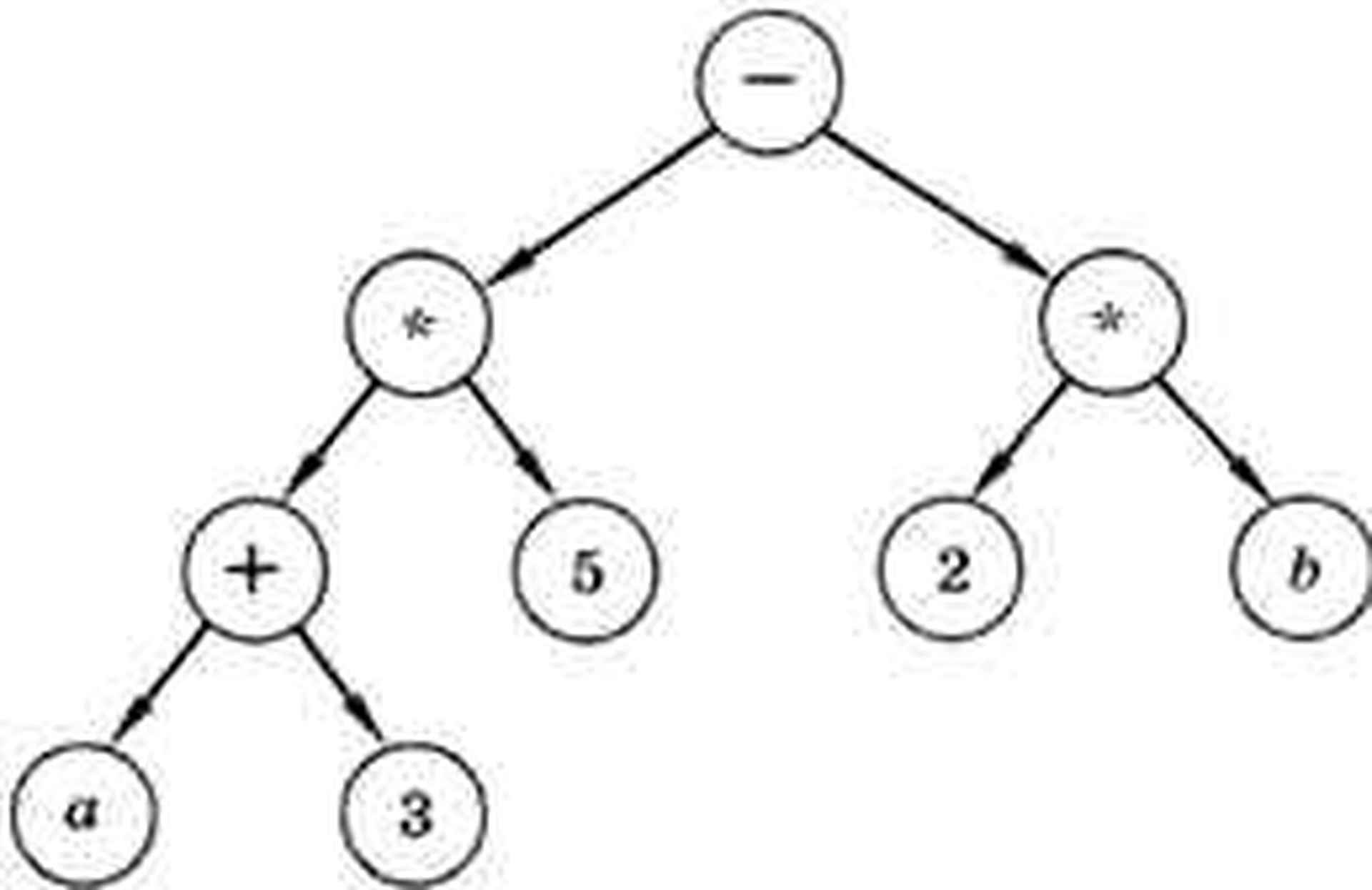
Здесь листья — это числа и переменные, тогда как корень и промежуточные вершины — знаки операций. Вычисления идут «снизу вверх», от листьев — к корню. Показанное дерево можно записать так:
(-(*(+ (а,3),5),*(2,b)))
Самое интересное, что скобки здесь необязательны; если их убрать, то выражение всё равно может быть однозначно вычислено:
- * + а 3 5 * 2 b
Такая запись, которая называется префиксной (операция записывается перед данными), просматривается с конца. Как только встретится знак операции, эта операция выполняется с двумя значениями, записанными справа.
В рассмотренном выражении сначала выполняется умножение:
- * + а 3 5 (2 * b)
затем — сложение:
- * (а + 3) 5 (2 * b)
и ещё одно умножение:
- (а + 3) * 5 (2*b)
и наконец, вычитание:
(а + 3) * 5 - (2 * b)
Для получения префиксной записи мы обходили все узлы дерева в порядке «корень — левое поддерево — правое поддерево». Действительно, сначала записана метка корня («-»), затем все метки левого поддерева, а затем — все метки правого поддерева. Для поддеревьев используется тот же порядок обхода. Если же обойти дерево в порядке «левое поддерево — правое поддерево — корень», получается постфиксная форма (операция после данных). Например, рассмотренное выше выражение может быть записано в виде
а З + 5 * 2 b * -
Для вычисления такого выражения скобки также не нужны, и это очень удобно для автоматических расчётов. Когда программа на языке программирования высокого уровня переводится в машинные коды, часто все выражения записываются в бесскобочной постфиксной форме и именно так и вычисляются. Постфиксная форма для компьютера удобнее, чем префиксная, потому что, когда программа доходит до знака операции, все данные для выполнения этой операции уже готовы.
ЗАДАНИЕ (сфотографировать и отправить в виде работы):
Представьте в виде дерева, префиксной и постфиксной записи выражение 2 + 4 * 5 - 3 / 1
и выражение 6 - 1 * 3 + 4